- Published on
Webhook Architecture Design
- Authors

- Name
- Tom Hacohen
- @TomHacohen
Svix founder and CEO Tom Hacohen sat down with our Head of Growth Ken Ruf to talk about webhook architecture and the best practices everyone sending webhooks at scale should follow.
For your convenience, here is the diagram which is frequently referenced throughout the call: 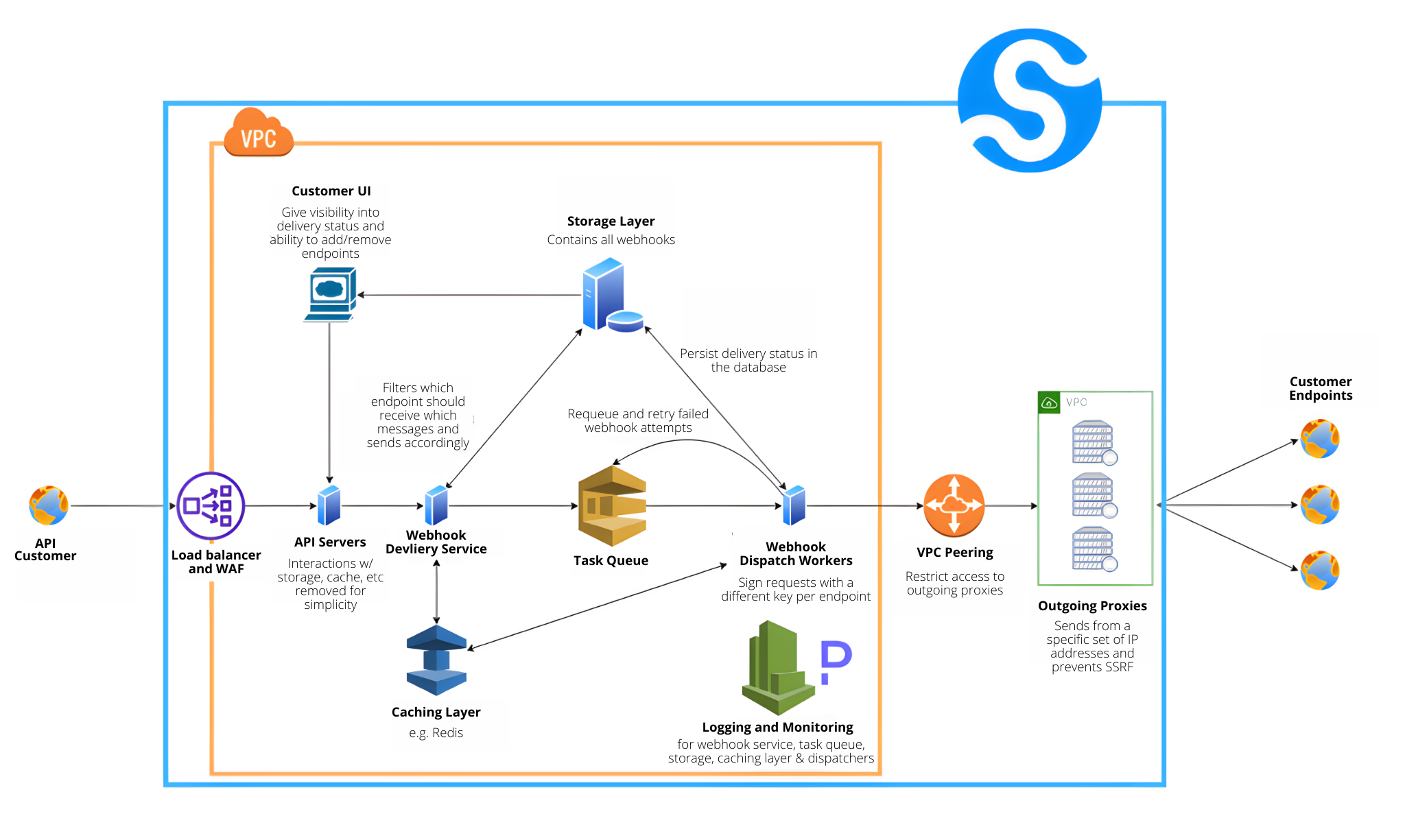
We also have a resource explaining the diagram and general best practices here.
Call transcript
Ken: Hi everyone. I'm Ken I'm in charge of growth at Svix and I'm here with my founder and CEO, Tom. Tom, how are you doing?
Tom: I'm good. Yourself?
Ken: I'm great. So we're here today to talk about webhook architecture. We've been getting a lot of questions, and interest in terms of what are some of the best practices around designing a webhook architecture, at scale. Tom like you wanna, yeah. So you wanna go through, we have a, we have a diagram that we've put together for Svix. We think this is kind of the baseline that people should be looking at. And generally speaking, Tom, like what are the, what are the things that you're optimizing for in the design?
Tom: Oh, you know, there's a lot, first of all, I mean, you have to think about scalability even, you know, I'm gonna talk about Svix as a service, but really it all applies. Even if you're running your internal webhook service, and you need to care about scalability, because you know, you're gonna be churning out a lot of Webhooks and you wanna make sure that your systems don't crash. you also want to think about security Webhooks come with like unique security implications.
There's the whole idea behind, you know, developer experience or customer experience your customers need to be able to see what's going on with the webhook, like where, where they sent, why did they fail? Did they fail and they have to manage, you know, like add URLs, be able to filter by there's just so much that goes into it.
You know, at the end of the day, webhooks are just HTTP requests. So it's, you know, it's easy to think that this is all you need just like one curl command, but actually there's so much more to it. Like there always is when you run like production environments.
Ken: mm-hmm . Okay. So do you wanna just take a look at the, the diagram now kind of go through like the different components that, that we have built out, kinda like what, what each, each kind of component is for and how they interact with each other.
Tom: Yeah, let's do that. so, okay, cool. When you look at the diagram, you can see, you know, the big, you know, the big blue rectangle, that's essentially what VIX does, but again, if you build it on your own, it's gonna, you know, it's gonna be your own web internal webhook service. that essentially does all of that give or.
I'm gonna talk about Svix, but almost everything applies, for if you build your own. So the first thing that you need to take take care of or have is an API service, essentially like a way to get your webhook request. So I wanna send a webhook into this webhook sending mechanism. It could be like using a queue or using like literally an HTTP server, which we have, or like whatever you want.
You most likely want a load balancer in front of that. Just because you wanna be able to scale, with your usage, but probably if you're just starting out and you're only sending like a, you know, a small number of webhooks a month, it's not that big of a deal. And we also have a WAF, so like a web application firewall, just for like an added layer of security.
But that's, you know, up to you. Yes.
Ken: Can I ask a quick question there?
Tom: Yeah.
Ken: Yeah. It's like, if I'm like a software provider, I already have like an API service. Is that something that I would already kind of have in place?
Tom: Yes and no. So yes, but you also, this would probably be like an internal API. So if you already mm-hmm you have a lot of microservices. This will look familiar. This will just be like one of your microservices.
Ken: Gotcha. So be kind of like its own piece.
Tom: Yeah, exactly. Gotcha. So as an, an internal fix, essentially, that's what you do.
Ken: Ah cool makes sense.
Tom: So, yeah, so let me just like continue going through the, the doc. So through the sorry, diagram, so first you have the API servers again, they, you know, they get this request, they interact with the database, you know, they decide, oh, should you know, Does this, you know, like a request is even allowed, is it allowed, should it be sent anywhere? Should it be filtered, et cetera. and part of it is like the web, you know, the webhook delivery service, essentially, kind of like decide what you want do with the webhook. the first thing you need to do when you get it is to persist it because you never wanna lose a message again, whether, whether are your external service like us or an internal microservice, you wanna make sure that you're eternally reliable there.
You know, one of the challenges about Webhooks compared to like a normal API is that a normal API is very much, constrained within the HTTP request. You make a request, something happens and there's a response. And if that request dies for whatever reason, it's all good because the client, the one making the API call will know that it failed and will know what to do with it.
But with the webhook service, they don't know that they expect a request. So you kind of like need to make sure, you know, have like this extra layer of reliability. So first thing you do, as I said, once you, you, first of all, persisted to a storage layer, once you've decided that you wanna send the webhook, you can add the task to a queue.
Then you have like a bunch of workers that will read from that queue. The reason why, I mean, they're like a lot of reasons, but like one of the main reasons, or one of the most naive ways to do a webhook implementation is just to make that HTTP call directly from that, you know, like API receiver that we talked about.
The reason why you don't want the webhook delivery service to make HTTP calls directly to customers is that customer endpoints may fail, may time out, may take a long time to respond and you don't wanna occupy your API. You know, your API endpoint, just like waiting on those and just like killing all the resources there.
So it's best practice to put it in the queue and just let background workers to, you know, to deal with it and make sure that things go as expected, and you know, even if they're like preoccupied, even they're overloaded, your API endpoints will still be able to, you know, listen to requests and get more stuff onto the queue.
That's the main thing with that obviously. The webhook dispatcher also needs to persist the status. So like what happened? What was the response, the response status code and write it back to storage. If for whatever reason that request fails, it'll want to requeue it. We have an exponentially, increasing retry schedule.
So you try immediately and then after five seconds and then after five minutes, and then after 30 minutes, et cetera, up to like two days in our case, but you can do whatever. Whatever you wanted, essentially giving those endpoints enough time to recover in case something goes wrong. So there could be your customers, customers have like, you know, like a three hour downtime that's okay.
Because the webhook is gonna be retried and retried over, over, over again, if you look at the bottom, there's like a caching layer. I mean, we use, Redis among other things, but, you know, Redis is great and they, you know, caching is always helpful, but I think it's extra important for like a, a webhook service, because you've gotta be sending a lot of Webhooks and you gotta be hitting the database quite a lot.
And it's very easy to succumb to the load so caching is paramount. And then at the bottom bottom, you see like logging and monitoring. So, you know, we talked about a queue, we talked about loads. We talked about like things being, all of this needs to be monitored because like, when you have a queue, the queue can maybe grow to infinity or can maybe have like significant delays.
You need to make sure that, you know, things actually like get processed from the queue that you need to make sure that the workers work and scale and all of that. So you really need a lot of monitoring. On top of all of that monitoring that is different to API calls because as I. With an HTTP request.
It's kinda like everything is constrained, you know, it's gonna be like everything that is interesting happens within the bounds of that request while with, you know, the webhook, it's kinda like everything happens asynchronously in the background.
Ken: And so to clarify on that, yeah, you're essentially saying it's like, because the webhook communication is effectively one way.
Tom: Right. If I send and the customer doesn't get something, they don't really know that, that, that something was sent to them and they didn't get it. And so logging and monitoring is a way for the users and also for yourself, I guess, to be like, okay, like what's failing and where. Yeah. So I was actually, this is a great point about the, you know, like not knowing about failure because as I said, You wanna monitor your API anyway, but even if you mess up and like, you don't have great monitoring, your customers are probably gonna let you know, like, Hey, your API stopped working.
You, you gotta get visibility into that. But with Webhooks, it's very much hidden. Like it's hard to know that things fail. It takes like more time to realize that things fail. So you need the extra monitoring on your hands to make sure that really you got everything covered and your systems are green.
Okay. And everything works. And what I was gonna touch on just now. Is that, and this is like the top left, corner of the, of the diagram is that you wanna give your customers visibility into the delivery status. because as you said, it's one way, like, you know, your server is letting their server know, they have no idea they're expecting a message. Right? So they need to, you know, need to be able to have visibility into like, what's going on. Like. Are things failing, where are they failing? Why are they failing? Was it like just a, you know, the internet is being crazy today or is it, you know, something on their end or something on your end.
And it's just, you know, this visibility makes their life much easier. And also your customer success or support, staff will really appreciate it. You know, to have all of this information available for them before they even need to reach out.
Ken: Okay. So there's like a component. Your customers need to be able to see what's wrong, but then there's also this extra component of, you need to figure out if something's wrong yourself because your customers aren't gonna be able to tell you
Tom: Yeah, exactly.
Ken: Gotcha. Okay.
Tom: Exactly that. And you know, one thing that, so we kinda like touched on the basic part of the system, and now we can touch a bit more like about the security aspects of it. So first of all, as you can see from the, from the orange square, everything is in a VPC. You know, first of all, that's just like, you know, best practice, just like compartmentalize stuff that should meet interaction with other stuff, to their own VPC.
But also, you know, like having the webhook system use its own database rather than the main database is often a good idea. Because as I said, like the webhook system can cause a lot of load and you don't want it to affecting your main systems, you know, like GitHub was down a few times in the last couple of months.
And it was partially because of the webhook system. So like their solution was to just kill or throttle Webhooks for like, you know, extended periods of time. And you don't want that happening to you. So just like segment it and make sure that, you know, this can scale on its own and it doesn't affect like other systems.
And now, so it's its own VPC and that's great. And what, and another thing that's important because Webhooks are essentially like a HTTP request from you to another entity. But this HTTP request is unauthenticated, there's no way to know where it came from. so the common way to secure that is to sign the requests and sorry. And essentially like most webhook implementation, they sign the request one way or another. you need to use a different key per endpoint. You don't wanna, you don't ever want to reuse, cryptographic keys. Usually you sign it using HMAC, SHA256. Some people use a symmetric, encryption, but that's, you know, that's a bad idea for performance.
And yeah, I mean, one, one common pitfall here is that people use insecure, hash functions like MD5 or SHA1, or sometimes they even use like secure, hash function, like SHA256, but they forget to, forget to verify the whole thing. So like, forget to verify the timestamp. So they're susceptible to, replay attacks or they don't use HMAC or they're, you know, susceptible to, length extension attack.
I forgot the name. The one when you, this is like a one, the reason why HMAC exist is like concatenating two strings and a hash is like, not a good idea. I think it's called length extension. Okay. One other, common security issue with Webhooks is called server side request forgeries, or SSRF essentially the problem there is that Webhooks you know, are HTTP calls that originate from within your VPC, so your private network, and they hit attacker controlled addresses. So normally, you know, the, the URLs would be api.example.com and that will hit somewhere, you know, on the internet. But oftentimes, or an attacker can abuse this and just have it pointing to an internal service.
So instead of calling an HTTP request to their service, they can just say, well, you know, make an HTTP request to the internal HR system or whatever, like other like internal system and do reconnaissance, or even that exfiltration, you know, directly from, using this mechanism. So what you wanna do, you wanna do two things.
Or like at least, you know, maybe more things even, but just like have multiple layers of, security. So one thing that we do, we it's recommended to use like a proxy. That proxy, just like filters and checks like the DNS of the request it's going to make and just make sure that the DNS is not is in the allow list.
Or at least it's not in the disallow list. Like it doesn't hit any subnets or any internal IPs. and the other thing is just like, again, for sanity, just put it in a different private network, so different VPC and just make it, so the first VPC can just call, you know, that request to this VPC and that VPC has no access to the previous one.
And the moment you do that, it kinda like you are, you know, you're secure, you know, that customers cannot have used your internal network. And then from, it just hits, you know, the customer endpoint. So, and that's it one, you know, once other small thing that it's important to think about, so that a lot of people neglect is that if you are making, you know, like if, if your customers are enterprise or like large organizations, oftentimes they would have, you know, like stronger or more stringent, security policies that were required them to have a file.
To only allow HTTP requests from like, a static set of IPs. And so it's very much important to only send webhooks from a specific set of IPs. So they, you know, they're able to, to allow it on their side and like allow it onto their firewall. And that's another reason why just sending from this, like one set of predefined proxies is so much important.
It's so important.
Ken: Is that like a, a business requirement that customers gonna have?
Tom: Yeah. I mean, sometimes just your, your customers may have, you know, you know, may have firewalls and they may need to know, you know, which PO, which, IP addresses to allow, just because of their, organizational policies.
And they will not be able to listen to your Webhook if you don't set from, if you don't send them for specific set of IPs.
Ken: Okay. That makes sense. It feels to me like most of these considerations are really about being able to scale. So like with a lot of database stuff, right. Making sure that things aren't get getting clogged anywhere.
Tom: Right. Mm-hmm, everything's flowing, flowing nicely. And then secondly, to make sure that like the, the customers have a good experience, right. So when things go wrong, it's easier for them to be able to actually identify what went wrong and to fix it essentially. Yeah. Exactly that it's like, you always want your customers happy and you always want your team happy, so you don't wanna make it, you know, like a maintenance hell for them.
So you wanna make sure that the, you know, the system just like work and scale automatically, et cetera.
Ken: So Tom, thanks for covering like the, the infrastructure side of things. Like. Is there something else that people should know about, like the features that they should be implementing? Like what is the actual like user experience that this infrastructure is?
Tom: Yeah. Okay. So I mean, one thing that we already briefly touched was, retries, you know, you wanna make sure that you try, you know, I mentioned the exponential backoff, but like, you don't wanna meet, delivery is paramount. Deliverability is paramount, sorry. And you wanna make sure that the webhooks get where they need to get to.
So you need to, you know, have like a robust retry mechanism in place. you also wanna know yourself when your delivery failed. Like maybe you tried delivering a webhook for 10 times, 12 times, 15 times, and it just failed and you are exhausted your retry schedule. You wanna be notified of that. In order to be able to notify the user, we, what we do is we send you a webhook ourselves to your systems.
If it's your own system, you can probably like send a webhook to your own internal, like microservice. just, you know, just like query the database occasionally and, and, you know, send a, you know, send an email. I don't know, whatever, you know, whatever works best in your scenario. And the other aspect to it is also, you know, like we, as I said, like, we, you, most services send a lot of webhooks and most customers only care about a subset of this webhook of this, of these Webhooks.
So one, one thing that is very common that most webhook system have is filtering by event. So event types are essentially a way of saying, this is what this event is about. So this one is about a user being created, or this one is about a user being deleted, and this is the schema that is associated with that event.
So kind of like your customers know exactly what to expect. And also like it's part of the system they want, they need to be able to say, well, I only care about user created and user deleted. I don't care about user modified. Or whatever. So they can filter the amount of webhooks that they receive.
This will ease the load on your system, but also on theirs. And the other thing is, you know, that we support, which, you know, I think is important, but maybe not essential depending on your scale is that we let you rate limit, you know, the webhooks you send to your customers. So oftentimes like our customers, we send us a lot of webhooks per second, like, you know, you know, multiple thousands, all that all meant to go to the same, customer for us. It's not a problem. You know, like we're a scalable API company. Like we can deal with this load. But the problem is, is that their customer is running like a tiny system with a tiny database and they are not equipped to deal with that.
So essentially like killing their all, you know, killing their system completely. Their system's like gonna be. The resources are gonna get exhausted and then you're gonna retry again. And that will also kill the, you know, like kill them even further. And you just are gonna like, you know, DOS them for like a while.
And so we just let our customers' customer define a rate limit and just say like, okay, I don't wanna get more than 10 requests per second. And we are gonna, you know, we're gonna absorb the load and like, kind of like unwind it for you and then you have like a few other nice to haves, that we do. For example, if, if you have a customer, like that's re responding to us with like a 429, so like too many requests, which like implies they're either, you know, like loaded on their own.
They just wanna like, rate limit us or like, like everyone else, or they just wanna rate limit us because we are overdoing it. We actually respect that. And add, you know, and kinda like add another smoothing layer on our own. And I think this is something that more webhook systems should do just like be a better net, and like, you know, interact between services, like in a nicer way.
Does that answer your question, Ken?
Ken: Yeah, I mean, I think the only other question that I might have. Right. That I can think of like, yeah. When you're starting out, like, let's say, you're you, you just got this, you know, request that, Hey, like we, we need webhooks. Right. And you're like, okay, like I need to design this system.
Like what, what is the first thing that you're gonna end up doing? Like, I would assume the first thing that you need to do is essentially like, kind of define your requirements. Right? First in terms of like what the system needs to enable. So like, do you have like a quick, like, kinda like hit list of like here, here are like the 5, 6, 7 things that it needs to do.
Tom: Yeah. So this is, this is gonna be subjective. Right. but I think that webhook systems that don't have it are at the greatest disadvantage. First thing, retries, you know, the whole point is to that, you know, I, I need to be able to trust it. So I need to know that it's gonna be delivered. If it only, you only try.
That sucks. and I, and you know, your customers cannot rely on it. Second thing, security, always important. Make sure that you signed the request. So I know it actually came from you signed the timestamp as well. So I know, you know, there's no like replay attack or anything else. One another thing is like fan out.
I wanna be able to add multiple webhook rails. I wanna, you know, maybe one is gonna hit Zapier and one is gonna hit Slack and one is gonna my main system and one is gonna hit my accounting system. I dunno. I want to be able to just like, you know, direct traffic to multiple directions. Otherwise I would just have to spin up my own server that does that, which is a bit annoying.
And as I said, like filtering by event types, I think is very important. Because first of all, it forces you to be diligent about defining the schemas and the events that you send, because it is an API after all. So you need to define it and have it consistent. And then the other aspect of it, is just like being able to filter by them so you can reduce the load.
You know, your customers can reduce the load and really only listen to the one or two events that they care about rather than the 50 others that they don't. I think those would be probably like my top. Oh, and one last thing, obviously. visibility. I wanna, you know, as, as your customer, I wanna be able to see.
Did the webhook get here? Well, like why did it fail and what was the response? Like all of that inform, you know, all of that information is like very important.
Ken: Okay. All right. Well, thanks Tom. I think, yeah, thank you. I think that's pretty good overview of kind of like our, our system, how it works and like what it's trying to do, right.
Like to enable all these features to make sure that if something goes wrong, you know, your customer knows and it can get fixed. And just to make sure everything's kind of just like running smoothly at scale.
Tom: Yeah, exactly.
Ken: All right. Thanks Tom. See you.
Tom: Thank you. Bye-bye.